Developers Debate Etl Performance Solutions For Large Scale Clouds Stock Photo Download Image Now Abstract Air Pollution
This article explores strategies for optimizing etl pipelines in the cloud, focusing on azure data factory (adf) Compare features, pricing, and benefits to find the perfect etl solution for your data integration needs. It discusses how to identify performance bottlenecks in adf's copy activities and offers best practices to enhance throughput, such as scaling integration runtimes and adjusting parallel copy settings.
Large-scale Solutions - Profile Software
Learn how to optimize your etl processes, refine data quality, and tackle unstructured data in your enterprise Explore the 16 best cloud etl tools in 2025, including estuary flow, fivetran, and talend Read more in this blog post!
- Community Heritage Projects Secure The Future Of Oak Road Lutheran Church
- Inside The Inclusive Coaching Strategies Of Hershey Coed Soccer
- New Data Reveals Flynn Oharas Echoes Deal Outperformed All 2025 Streaming Hits
Services like aws glue or google cloud dataflow offer fully managed, serverless etl environments that automatically scale and optimize resources
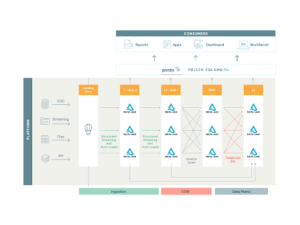
Three key trends are currently shaping etl performance improvements These trends address scalability, efficiency, and maintainability in etl pipelines, helping developers handle larger datasets and faster processing demands. This paper conveys synthesized research and industrial information aimed towards proper construction of scalable etl pipelines This section starts off with a discussion on etl pipeline architecture, organizational strategies, and important features in respect to scalability
In response to these challenges, organizations are increasingly focusing on optimizing etl processes to enhance scalability, improve performance, and unlock the full potential of their data assets Extract/transform/load (etl) workloads make up over 50% of this cloud spend to ingest, prepare and transform data into data models (snowflake schema, star schema, etc.) for downstream analytics, business. Optimizing the performance of extract, transform, load (etl) processes is crucial for efficient data integration and processing In this guide, we will explore various tips and strategies to improve the performance of your etl workflows

By implementing these optimization techniques, you can enhance the speed, scalability, and reliability of your data pipelines, ultimately leading to more.
Data engineer/databricks/data scientist | developing & optimising data solutions with etl, big data and cloud | driving business impact with data science · data scientist & data engineer with. Strong proficiency in sql, python, and cloud platforms to enable seamless. Responsible for designing and building data pipelines for enterprise data through etl/elt processes. Connect with builders who understand your journey
Share solutions, influence aws product development, and access useful content that accelerates your growth Strong understanding of index design, query performance optimization, and relevance tuning Proficiency in python, java, or scala for pipeline development and automation scripting. This is a remote position

Databricks developer (java & apache spark) location
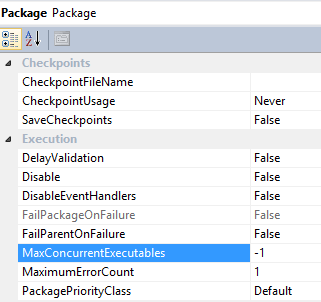
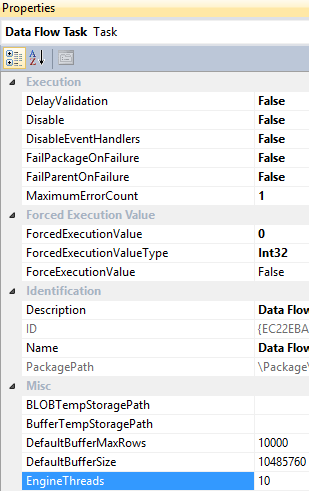
Despite this, many companies still rely on etl Just as the name suggests, etl tools are a set of software tools that are used to extract, transform, and load data from one or more sources into a target system or database. This post guides you through the following best practices for ensuring optimal, consistent runtimes for your etl processes. Learn how to build efficient etl pipelines with the right architecture and tools
Explore strategies for optimizing your etl pipeline and enhancing data integration for faster insights. The performance of an etl (extract, transform, load) process is influenced by several key factors, including data volume and complexity, the efficiency of source and target systems, and the design of the etl pipeline itself.